机器之心 JIQIZHIXIN (@jiqizhixin)
2026-02-01 | ❤️ 172 | 🔁 22 | 💬 2
What if your robot or car could see depth more clearly than a top-tier RGB-D camera?
Researchers from Ant Group present LingBot-Depth.
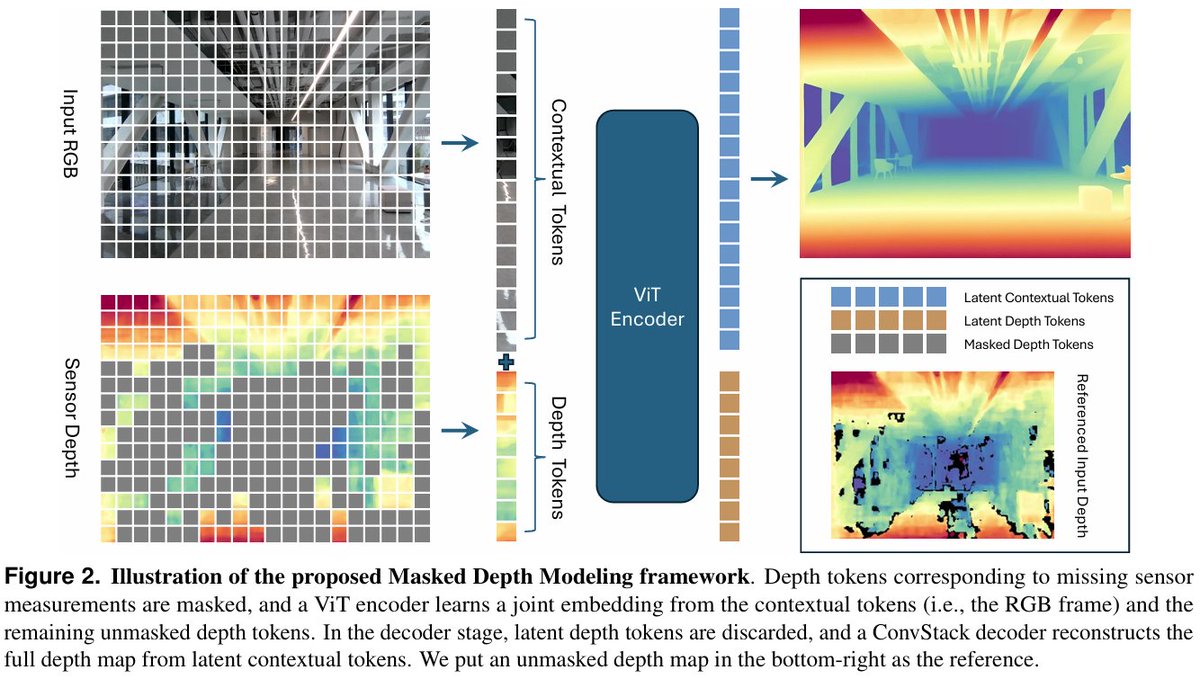
It treats sensor errors as “masked” clues, using visual context to intelligently fill in and refine incomplete depth maps.
It outperforms leading hardware in both precision and coverage, creating a unified understanding of color and depth for robotics and autonomous driving.
Masked Depth Modeling for Spatial Perception
Project: https://technology.robbyant.com/lingbot-depth HuggingFace: https://huggingface.co/robbyant/lingbot-depth Paper: https://github.com/Robbyant/lingbot-depth/blob/main/tech-report.pdf
Our report: https://mp.weixin.qq.com/s/_pTyp6hwmnLQUEeEzdp2Qw
📄 원문 내용
Robbyant - Exploring the frontiers of embodied intelligence. We focus on foundational large models for embodied AI: LingBot-Depth (spatial perception), LingBot-VLA (vision-language-action), LingBot-World (world models), LingBot-VA (video action). Technology-driven, building an AGI platform for the physical world. 灵波科技 - 探索具身智能的上限。专注具身智能基础大模型:LingBot-Depth 空间感知、LingBot-VLA 视觉-语言-动作、LingBot-World 世界模型、LingBot-VA 视频动作。技术驱动,打造物理世界的 AGI 平台。
robbyant/lingbot-depth · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
lingbot-depth/tech-report.pdf at main · Robbyant/lingbot-depth · GitHub
Masked Depth Modeling for Spatial Perception. Contribute to Robbyant/lingbot-depth development by creating an account on GitHub.
미디어
🔗 Related
- bringing-foundation-models-to-depth-sensing-defm-is-trained- — 도메인: Vision/3D, Robotics/Manipulation
- lingbot-depth-masked-depth-modeling-for-spatial-perception-941785 — 도메인: Vision/3D, Robotics/Manipulation
- so-proud-of-our-ucla-vail-students-we-have-4-papers-accepted — 도메인: Vision/3D, Robotics/Manipulation
- dynamicvla — 도메인: Robotics/Manipulation
- our-model-predicts-metric-scale-pixel-aligned-and-dense-dept — 도메인: Vision/3D