机器之心 JIQIZHIXIN (@jiqizhixin)
2025-12-28 | ❤️ 160 | 🔁 25
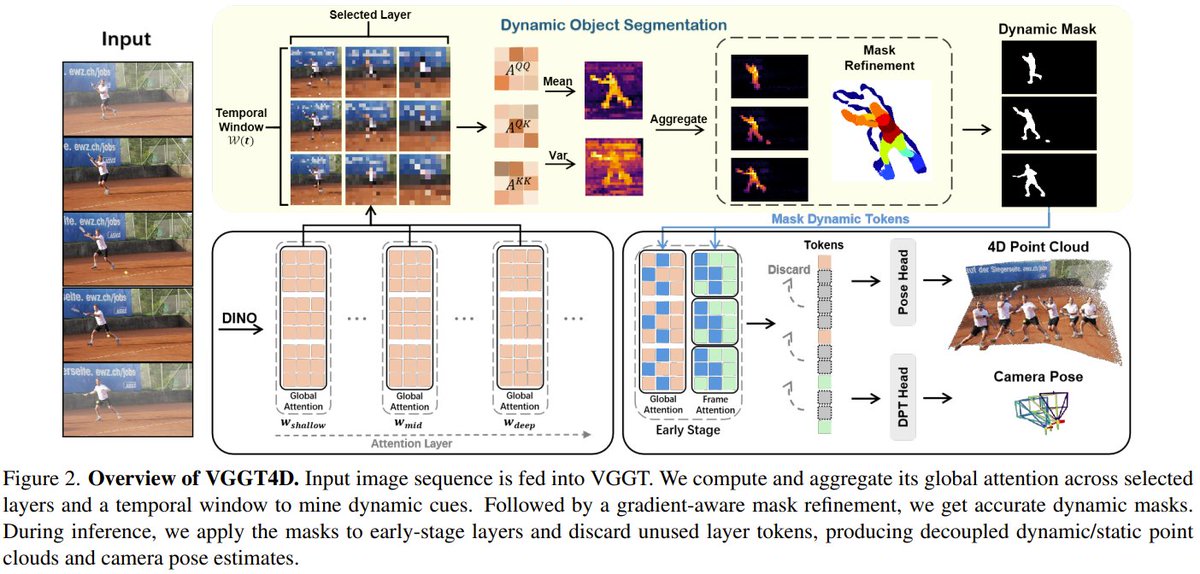
How do you reconstruct a 4D world from video when everything is moving? Researchers from HKUST & Horizon Robotics have a new, training-free answer.
They built VGGT4D. It cleverly mines the “motion cues” already hidden inside a powerful 3D AI model (VGGT), using them to automatically separate dynamic objects from the static scene.
The result? It outperforms existing methods in dynamic object segmentation, camera tracking, and 3D reconstruction across six benchmarks—and can process over 500 frames in a single pass.
VGGT4D: Mining Motion Cues in Visual Geometry Transformers for 4D Scene Reconstruction
Paper: https://arxiv.org/abs/2511.19971 Project: https://3dagentworld.github.io/vggt4d/ Code: https://github.com/3DAgentWorld/VGGT4D
Our report: https://mp.weixin.qq.com/s/FtZc3LrDHfD9FxImWunk3g
📬 PapersAccepted by Jiqizhixin
🔗 원본 링크
- https://arxiv.org/abs/2511.19971
- https://3dagentworld.github.io/vggt4d/
- https://github.com/3DAgentWorld/VGGT4D
- https://mp.weixin.qq.com/s/FtZc3LrDHfD9FxImWunk3g
미디어
🔗 Related
- chain-of-view-makes-vision-language-models-move-through-a
- what-if-sim-and-reality-were-one-this-system-keeps-them-in
- gaussianfluent-explicit-gaussian-simulation-for-dynamic
- luxremix-lighting-decomposition-and-remixing-for-indoor
- exciting-new-work-on-detailed-pixel-level-dense-3d-visual