Why does LLM-generated code still fail to compile or run correctly even with advanced models?
Why does LLM-generated code still fail to compile or run correctly even with advanced models?
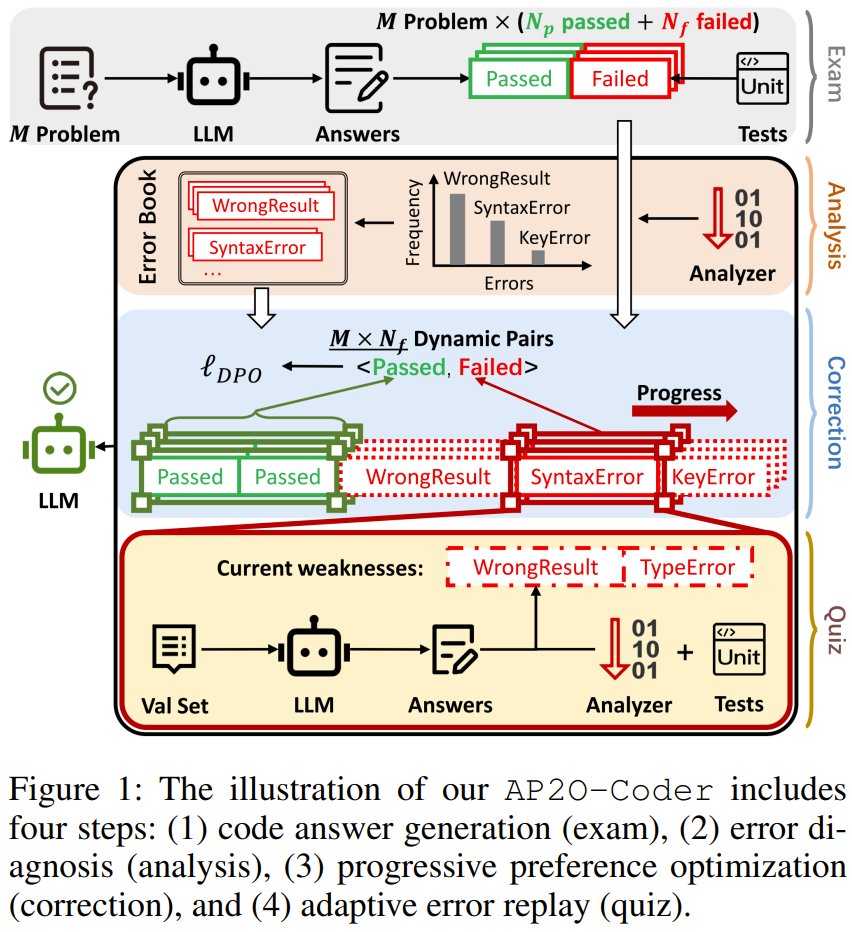
Shanghai Jiao Tong University and Tencent present AP2O-Coder, a new approach that analyzes specific error types in failed code and trains AI to fix them step by step, adapting to each model’s weaknesses.
The method improves code generation performance by up to 3% in pass@k while using significantly less preference data across multiple LLM families including Llama, Qwen, and DeepSeek.
AP2O-Coder: Adaptively Progressive Preference Optimization for Reducing Compilation and Runtime Errors in LLM-Generated Code
Paper: https://arxiv.org/pdf/2510.02393 Code: https://github.com/TsingZ0/AP2O
Our report: https://mp.weixin.qq.com/s/gmVmOFOjk51WQZJsjA9x-g
📬 PapersAccepted by Jiqizhixin
🔗 원본 링크
- https://arxiv.org/pdf/2510.02393
- https://github.com/TsingZ0/AP2O
- https://mp.weixin.qq.com/mp/wappoc_appmsgcaptcha?poc_token=HLsHh2mjHgYjWDawwzU-v07fCdhP0GJJtcQKnJtF&target_url=https%3A%2F%2Fmp.weixin.qq.com%2Fs%2FgmVmOFOjk51WQZJsjA9x-g
미디어