Aurimas Griciūnas (@Aurimas_Gr)
2025-01-15 | ❤️ 311 | 🔁 71
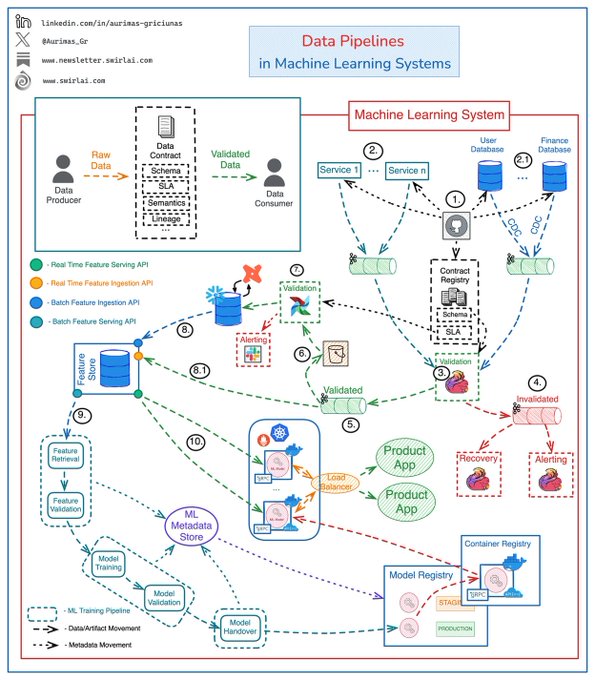
𝗗𝗮𝘁𝗮 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲𝘀 𝗶𝗻 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗦𝘆𝘀𝘁𝗲𝗺𝘀 can become complex and for a good reason 👇
It is critical to ensure Data Quality and Integrity upstream of ML Training and Inference Pipelines, trying to do that in the downstream systems will cause unavoidable failure when working at scale.
It is a good idea to start thinking about the quality of your data at the point of creation (the producers). This is where you can also start to utilise Data Contracts.
Example architecture for a production grade end-to-end data flow:
𝟭: Schema changes are implemented in version control, once approved - they are pushed to the Applications generating the Data, Databases holding the Data and a central Data Contract Registry.
[𝗜𝗺𝗽𝗼𝗿𝘁𝗮𝗻𝘁]: Ideally you should be enforcing a Data contract at this stage, when producing Data. Data Validation steps down the stream are Detection and Prevention mechanisms that don’t allow low quality data to reach downstream systems. There might be a significant delay before you can do those checks, causing irreversible corruption or loss of data.
Applications push generated Data to Kafka Topics:
𝟮: Events emitted directly by the Application Services.
👉 This also includes IoT Fleets and Website Activity Tracking.
𝟮.𝟭: Raw Data Topics for CDC streams.
𝟯: A Flink Application(s) consumes Data from Raw Data streams and validates it against schemas in the Contract Registry. 𝟰: Data that does not meet the contract is pushed to Dead Letter Topic. 𝟱: Data that meets the contract is pushed to Validated Data Topic. 𝟲: Data from the Validated Data Topic is pushed to object storage for additional Validation. 𝟳: On a schedule Data in the Object Storage is validated against additional SLAs in Data Contracts and is pushed to the Data Warehouse to be Transformed and Modeled for Analytical purposes. 𝟴: Modeled and Curated data is pushed to the Feature Store System for further Feature Engineering. 𝟴.𝟭: Real Time Features are ingested into the Feature Store directly from Validated Data Topic (5).
👉 Ensuring Data Quality here is complicated since checks against SLAs is hard to perform.
𝟵: High Quality Data is used in Machine Learning Training Pipelines. 𝟭𝟬: The same Data is used for Feature Serving in Inference.
Note: ML Systems are plagued by other Data related issues like Data and Concept Drifts. These are silent failures and while they can be monitored, we don’t include it in the Data Contract.
Let me know your thoughts! 👇
MachineLearning DataEngineering AI
Want to learn first principals of Agentic systems from scratch? Follow my journey here: https://www.newsletter.swirlai.com/p/building-ai-agents-from-scratch-part
🔗 원본 링크
미디어
🔗 Related
Auto-generated - needs manual review