机器之心 JIQIZHIXIN (@jiqizhixin)
2026-01-04 | ❤️ 128 | 🔁 23
What if you could make a robot’s AI brain more stable and reliable at test time, without expensive retraining?
Researchers from China Telecom AI Institute, Tsinghua University, HKUST, and USTC present TACO.
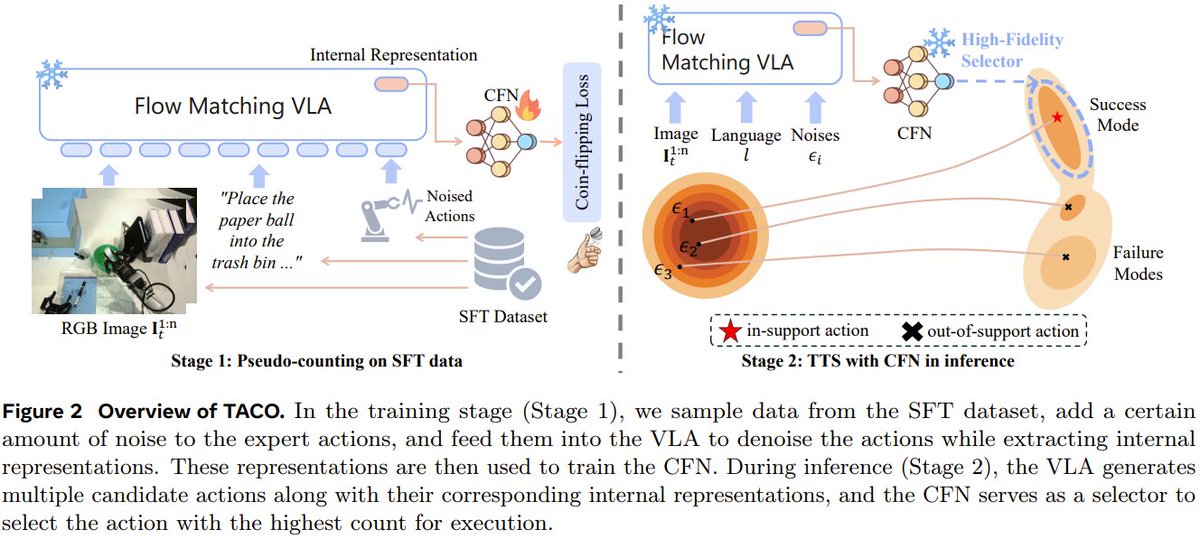
They fix a key flaw in robot AI models (VLAs): after fine-tuning, they can generate shaky, inconsistent actions. TACO acts as a lightweight “action verifier” at inference, picking the most reliable action from multiple options.
It significantly boosts success rates & stability in robot simulations, outperforming standard fine-tuning methods.
Steering Vision-Language-Action Models as Anti-Exploration: A Test-Time Scaling Approach
Paper: https://arxiv.org/abs/2512.02834 Project: https://vla-anti-exploration.github.io/ Code: https://github.com/breez3young/TACO/
Our report: https://mp.weixin.qq.com/s/t3u7Iv6es3XMTJTZmSYeHA
📬 PapersAccepted by Jiqizhixin
🔗 원본 링크
- https://arxiv.org/abs/2512.02834
- https://vla-anti-exploration.github.io/
- https://github.com/breez3young/TACO/
- https://mp.weixin.qq.com/s/t3u7Iv6es3XMTJTZmSYeHA
미디어
🔗 Related
Auto-generated - needs manual review