Philippe Hansen-Estruch (@tokenpilled65B)
2026-01-20 | ❤️ 413 | 🔁 58
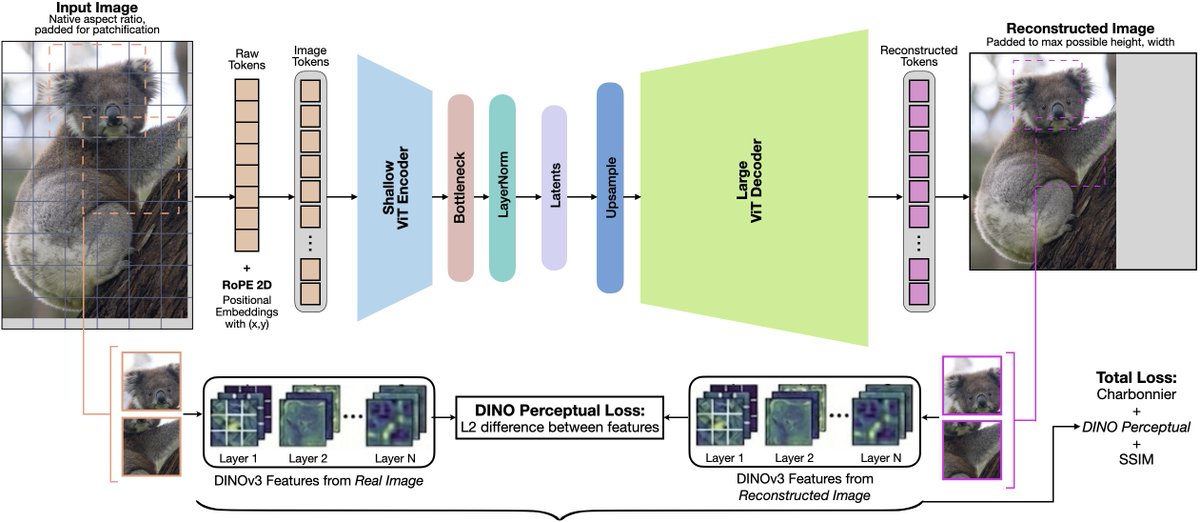
Releasing ViTok-v2: open-source ViT auto-encoder codebase + pretrained weights
Train your own ViT auto-encoder on any streamed (hf://) or local webdataset. NaFlex pipeline handles any resolution and aspect ratio
Includes reproduced 350M and 4.5B models weights competitive at 256p, SOTA at high-res (512p+)
미디어