MrNeRF (@janusch_patas)
2025-01-08 | ❤️ 140 | 🔁 12
Once upon a time, C received an upgrade - it was called C++.
Today, DuSt3R gets its own upgrade: The implementation code of DuSt3R+ is dropping now. Have fun!
P.S.: Code in the comments!
🔗 Related
Auto-generated - needs manual review
인용 트윗
MrNeRF (@janusch_patas)
MV-DUSt3R+: Single-Stage Scene Reconstruction from Sparse Views In 2 Seconds
Contributions:
• We present MV-DUSt3R, a novel feed-forward network for pose-free scene reconstruction from sparse multi-view input. It not only runs 48 ∼ 78× faster than DUSt3R for 4 ∼ 24 views but also reduces Chamfer distance on three challenging evaluation datasets: HM3D (Ramakrishnan et al., 2021), ScanNet (Dai et al., 2017), and MP3D (Chang et al., 2017) by 2.8×, 2×, and 1.6× for smaller scenes of average size 2.2, 7.5, 19.3 (m²) with 4-view input, and 3.2×, 1.9×, and 2.1× for larger scenes of average size 3.3, 17.9, 37.3 (m²) with 24-view input.
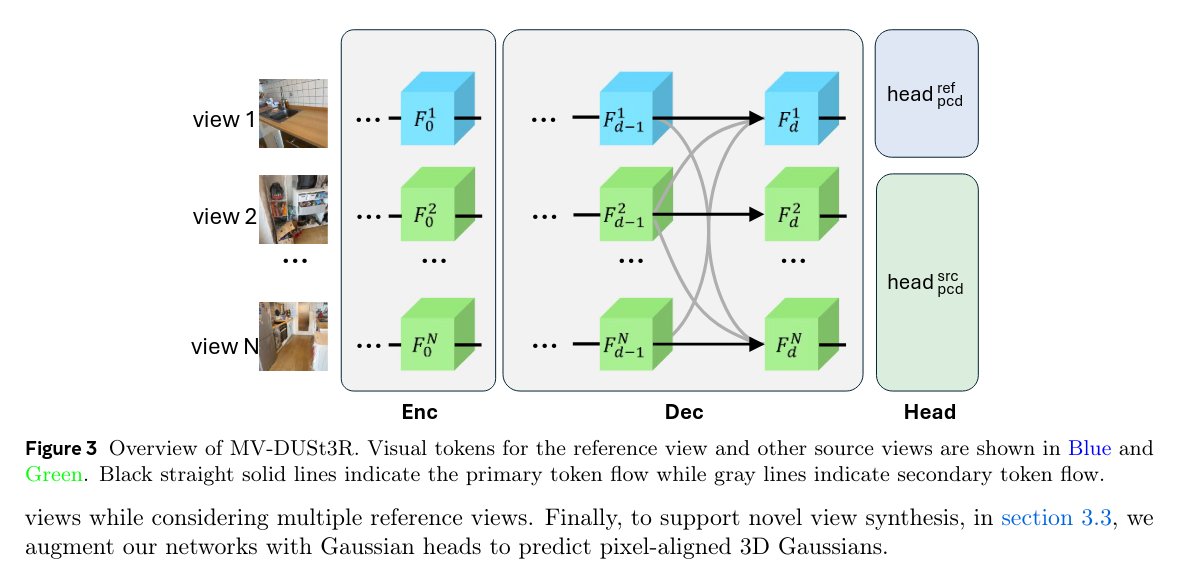
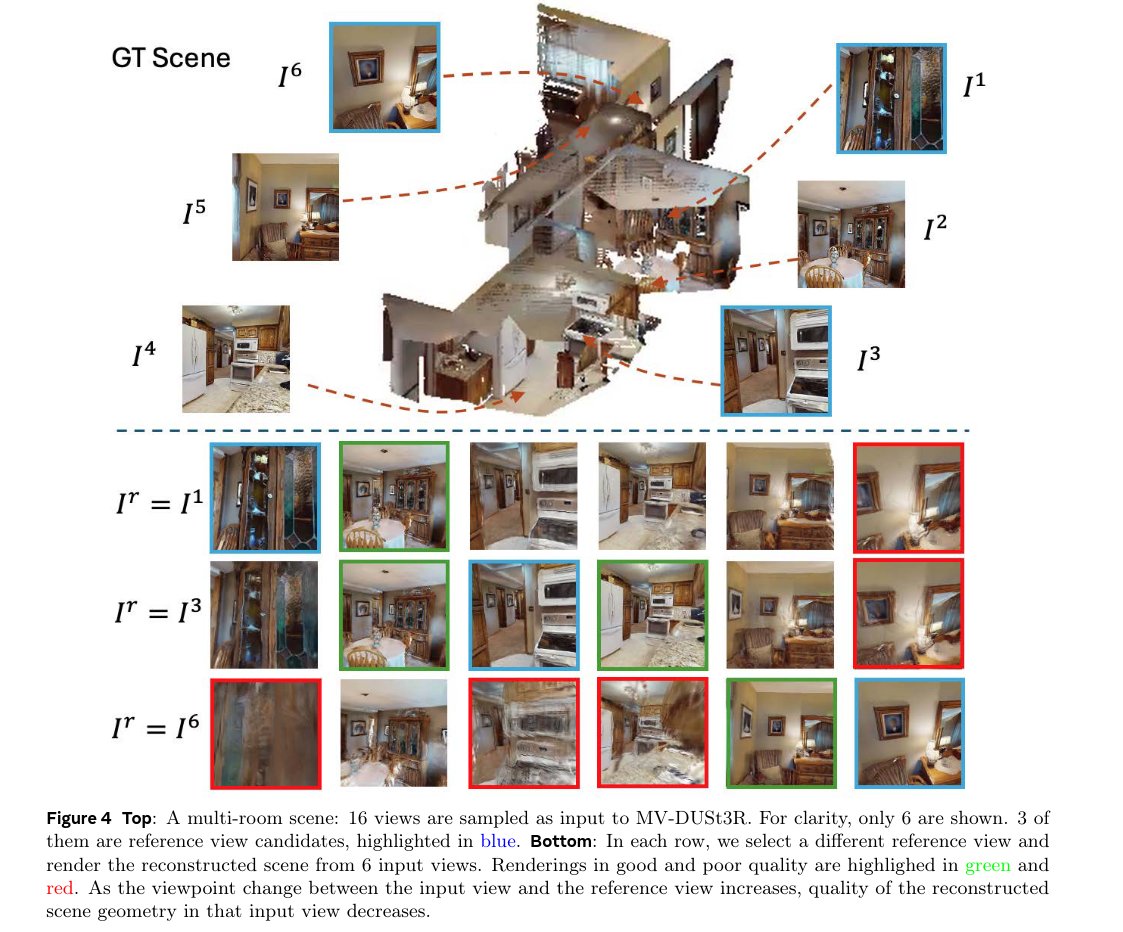
• We present MV-DUSt3R+, which improves MV-DUSt3R by using multiple reference views, addressing the challenges that occur when inferring relations between all input views via a single reference view. We validate that MV-DUSt3R+ performs well across all tasks, number of views, and on all three datasets. For example, for MVS reconstruction, it further reduces Chamfer distance on three datasets by 2.6×, 1.6×, and 1.8× for large scenes with 24-view input while still running 14× faster than DUSt3R.
• We extend both networks to support NVS by adding Gaussian splatting heads to predict per-pixel Gaussian attributes. With joint training of all layers using both reconstruction loss and view rendering loss, we demonstrate that the model significantly outperforms a DUSt3R-based baseline.