Tanishq Mathew Abraham, Ph.D. (@iScienceLuvr)
2025-04-29 | ❤️ 238 | 🔁 34
NORA: A Small Open-Sourced Generalist Vision Language Action Model for Embodied Tasks
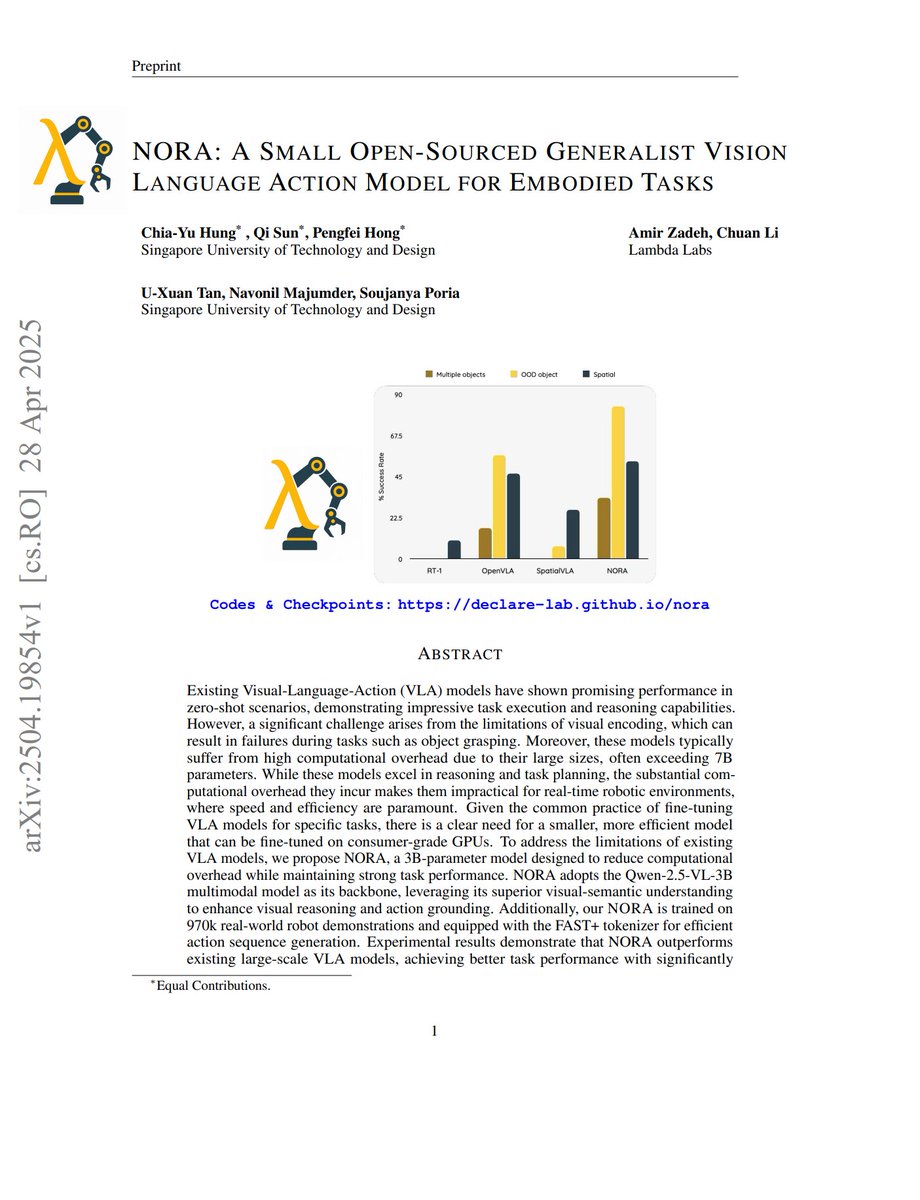
“we propose NORA, a 3B-parameter model designed to reduce computational overhead while maintaining strong task performance. NORA adopts the Qwen-2.5-VL-3B multimodal model as its backbone, leveraging its superior visual-semantic understanding to enhance visual reasoning and action grounding. Additionally, our NORA is trained on 970k real-world robot demonstrations and equipped with the FAST+ tokenizer for efficient action sequence generation. Experimental results demonstrate that NORA outperforms existing large-scale VLA models, achieving better task performance with significantly reduced computational overhead, making it a more practical solution for real-time robotic autonomy.”
미디어
🔗 Related
Auto-generated - needs manual review
Tags
domain-robotics domain-ai-ml domain-vlm domain-crypto domain-visionos