Bunty (@Bahushruth)
2025-04-21 | ❤️ 908 | 🔁 98
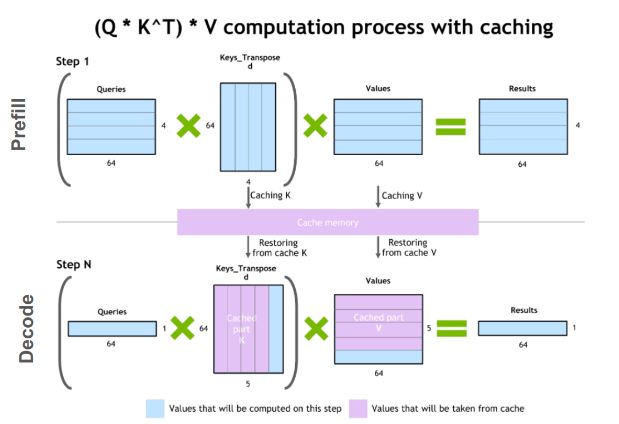
Ever wondered how to run a 600B+ parameter LLM for millions of users? Here is an info dump from reading a lot about LLM inference and shipping infra with thousands of GPUs in production.
I also tried to explain @nvidia’s new framework for handling multi node inference👇 https://x.com/Bahushruth/status/1914394705309143402/photo/1
🔗 원본 링크
미디어
🔗 Related
Auto-generated - needs manual review