Muyu He (@HeMuyu0327)
2025-12-17 | ❤️ 359 | 🔁 43
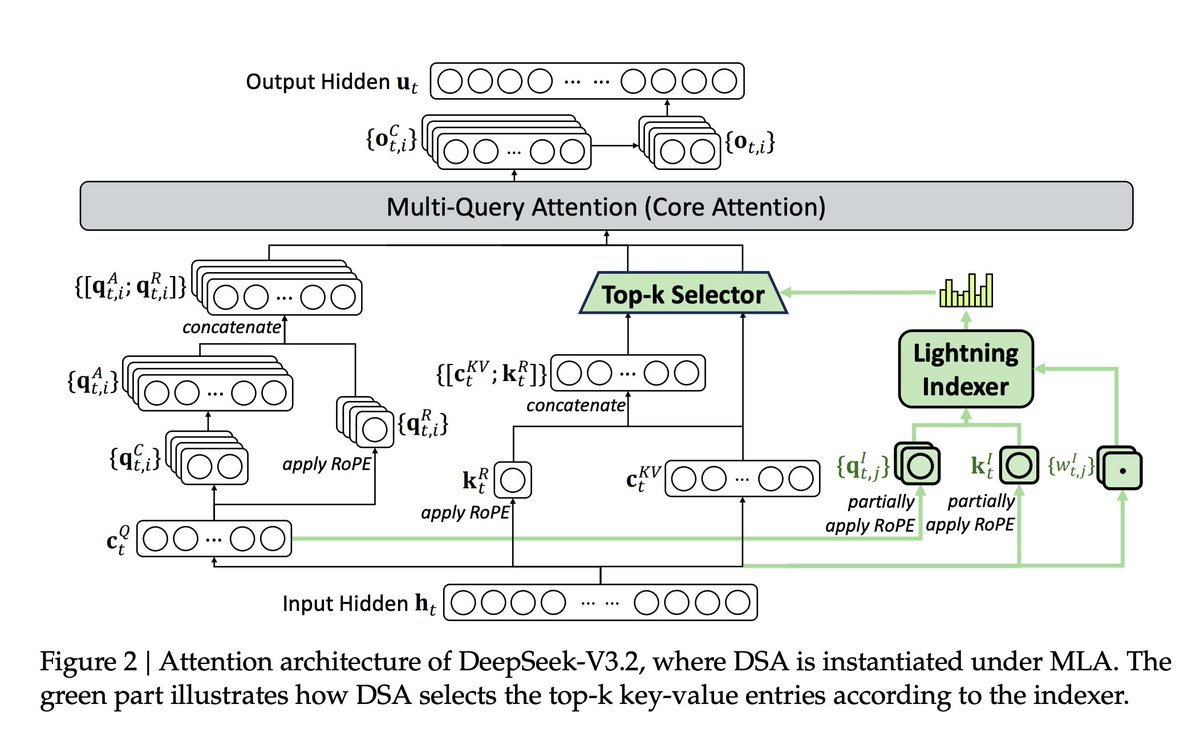
DeepSeek v3.2 has a very complex figure in the paper to explain DeepSeek Attention (DSA), so I simplified it with reference to their source code.
What is novel: DSA introduces an indexer to select the top-k most relevant key tokens relative to a query token, making attention sparse.
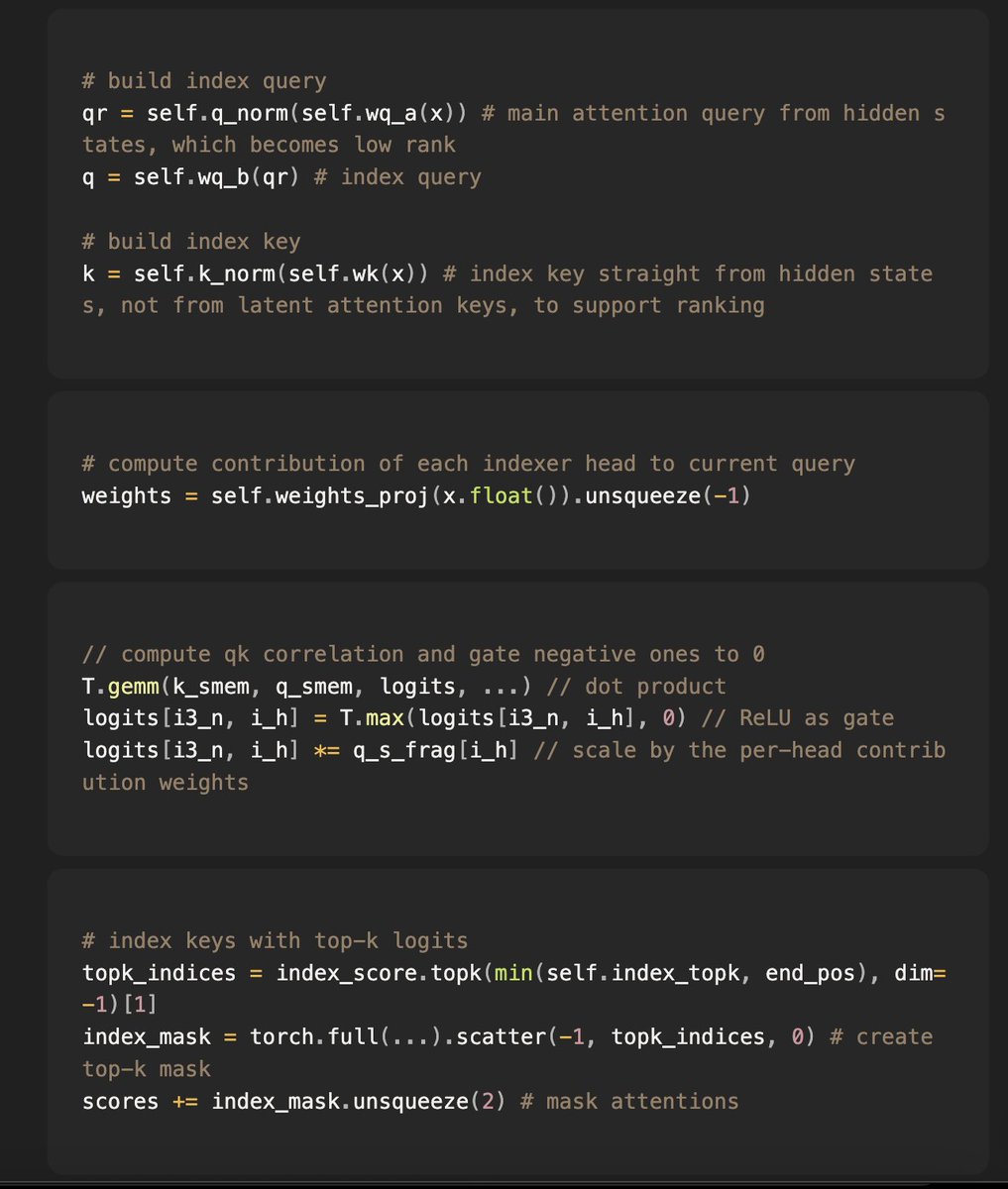
How the indexer works: my pseudocode breaks it down to three steps (p1), ie.
-
Compute the indexer query and the indexer keys across “indexer heads”, which can be more optimized for ranking and retrieval than attention QKs
-
Compute a weighting of each indexer head based on how relevant they are to the current query
-
Compute indexer scores with regular scaled dot product, and then gate (using ReLU) + scale (using the head weight) the indexer scores to get the relevancy scores
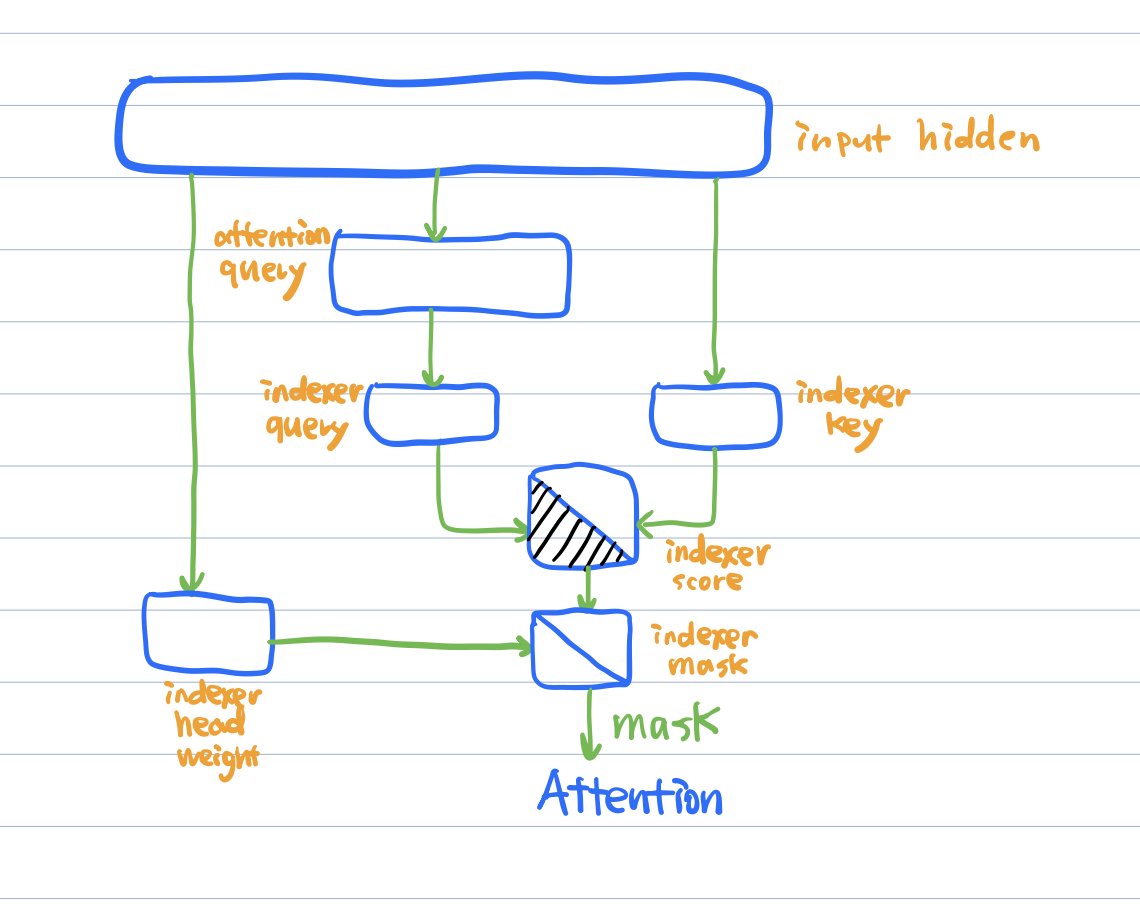
After these three steps, the indexer will output an index mask (see the figure in p2), which will replace the causal mask in their regular MLA attention.
Important caveats:
-
Indexer queries are computed from attention queries, not input hidden states, because we want to index the most relevant information relative to the query vectors that will go into attention
-
Indexer keys and head weights are however computed from hidden states, not attention keys, because we want to learn specific patterns from tokens that are good for ranking and retrieval
Cool optimizations: the indexer and the MLA are computed and cached in fp8, with clever optimizations (caching the scaling factor, rotate the activations) to make the quantization less lossy
In the end, we get a sparse attention pattern that powers DeepSeek v3.2. An inspiring design. Personally I am curious whether familiar phenomena such as attention sinks will emerge here as well.
미디어