Zhe Gan (@zhegan4)
2024-10-04 | ❤️ 927 | 🔁 154
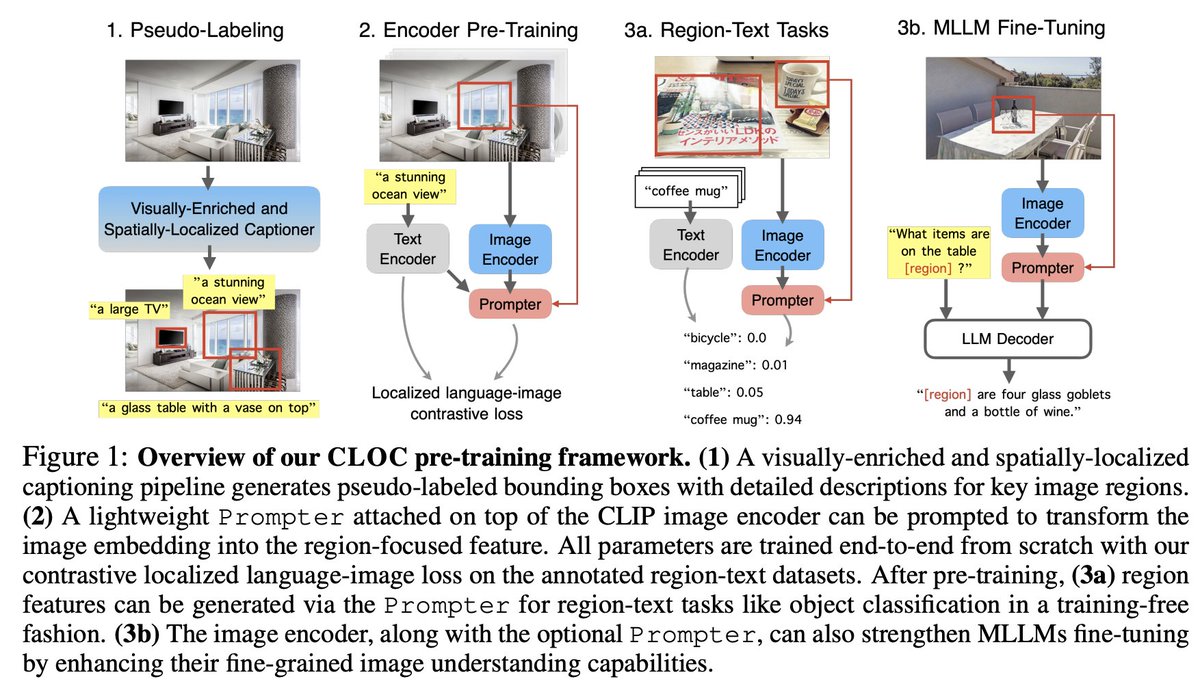
💡CLIP is the default choice for most multimodal LLM research. But, we know CLIP is not perfect. It is good at high-level semantics, but not for capturing fine-grained info.
🤩🤩 We present CLOC ⏰, our next-generation image encoder, with enhanced localization capabilities, and serves as a drop-in replacement for CLIP.
🚀🚀How to do that? We conduct large-scale pre-training with region-text supervision pseudo-labelled on 2B images.
🎁As a result, CLOC is indeed a better image encoder, not only for zero-shot image/region tasks, but also for multimodal LLM.
미디어