Embodied AI Reading Notes (@EmbodiedAIRead)
2026-01-18 | ❤️ 349 | 🔁 44
1X World Model | From Video to Action: A New Way Robots Learn
Blog: https://www.1x.tech/discover/world-model-self-learning
1X describes and shows initial results for a new potential way of learning robot policy using video generation based world modeling, compared to VLA which is based on VLM.
-
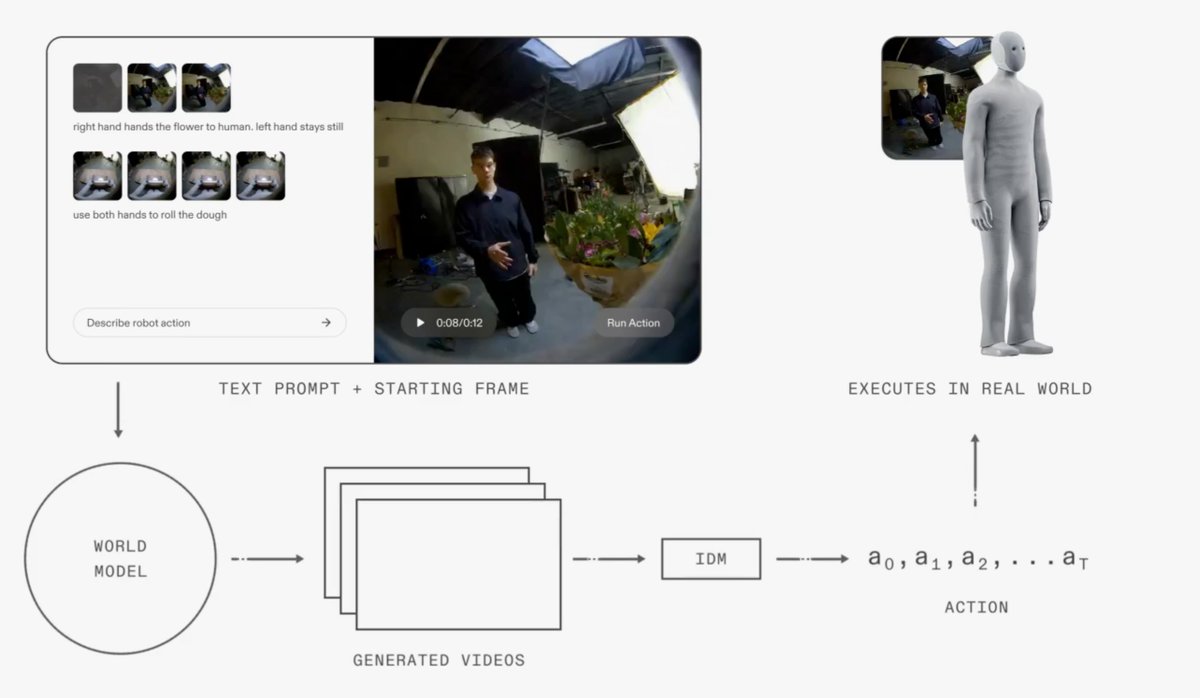
How it works: at inference time, the system receives a text prompt and a starting frame. The World Model rolls out the intended future image frames, the Inverse Dynamics Model extracts the trajectory, and the robot executes the sequence in the real world.
-
The World Model backbone: A text-conditioned diffusion model trained on web-scale video, mid-trained on 900 hours of egocentric human data of first-person manipulation tasks for capturing general manipulation behaviors, and fine-tuned on 70 hours of NEO-specific sensorimotor logs for adapting to NEO’s visual appearance and kinematics.
-
The Inverse Dynamics Model: similar to architecure used in DreamGen, and trained on 400 hours of robot data on random play and motions.
-
Results: The model can generate videos aligning well with real-world execution, and the robot can perform object grasping, manipulation with some degree of generalization.
-
Current limitations: The pipeline latency is high and it’s not lose-loop. Currently the WM takes 11 second to generate 5 second video on a multi-GPU server and IDM takes another 1 second to extract actions.
🔗 원본 링크
미디어
🔗 Related
Auto-generated - needs manual review